
GraphQL has become a popular alternative to traditional RESTful APIs, offering a more efficient and flexible way for clients to retrieve data. Instead of making multiple calls to various endpoints and receiving fixed response formats—as is common with REST—GraphQL enables clients to request exactly the data they need in a single request. This eliminates issues like over-fetching and under-fetching and gives frontend developers precise control over the data structure.
AWS AppSync is a fully managed service that simplifies the creation of scalable, real-time GraphQL APIs. It integrates smoothly with AWS services like DynamoDB, Lambda, RDS, and OpenSearch, and includes built-in support for features such as real-time subscriptions, offline access, and fine-grained access control. AppSync handles much of the complexity around scalability and security, so developers can focus on defining data models and resolver logic.
Resolvers in AppSync are the key components that connect GraphQL fields to underlying data sources. Each field—including nested ones—can have its own resolver, which is triggered when a query is executed. These resolvers can use Velocity Template Language (VTL) or invoke Lambda functions to map requests and responses. While this approach provides flexibility, it can lead to performance issues—especially the N+1 query problem—when dealing with nested relationships.
In this post, we’ll dive into how the N+1 problem arises in AWS AppSync, why it poses challenges at scale, and how to build optimized resolvers using batching techniques and Lambda-based solutions to improve performance.
When working with GraphQL, it’s common to request nested data in a single query. AppSync supports this by allowing each field — including deeply nested ones — to have its own resolver that fetches data from a backend data source. While this design provides flexibility and modularity, it can lead to an inefficient execution pattern known as the N+1 problem.
The N+1 problem usually occurs with list queries. When your GraphQL API ends up making one query to fetch the root items (1), and N additional queries for each nested field, where N is the number of root items returned in the list.
Let’s take an example to understand this clearly.
query {
books {
name
title
author {
firstnName
lastName
}
}
}
Here’s what typically happens behind the scenes in AppSync
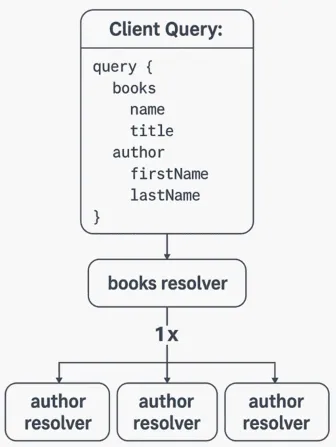
In total, that’s 1 + 100 = 101 (N+1) resolver invocations for a single client query.
If you have even more nested queries, this becomes worse. In the below query, there is an additional field (address) that requires more resolver invocations.
query {
books {
name
title
author {
firstName
lastName
address {
city
state
}
}
}
}
In total, that’s 1 + 100 + 100 = 301 resolver invocations for a single client query.
This approach scales poorly:
While this might be acceptable for small datasets or low traffic, the N+1 pattern becomes a serious performance bottleneck at scale. Imagine serving thousands of queries per second — this inefficient pattern can overwhelm backend systems, increase response times, and degrade the user experience.
One of the most effective ways to overcome the N+1 problem in AWS AppSync is by using batch resolvers. The idea is simple: instead of resolving nested fields one-by-one (which results in many resolver calls), we batch them together into a single call , usually handled by a Lambda function.
Let’s explore how this works and why it’s such a powerful pattern.
In AppSync, each nested field (such as author or address) can have its own resolver, which is typically invoked for each parent object.
To convert this into a batch operation:
Let’s apply this to our previous query and see how this works.
query {
books {
name
title
author {
firstName
lastName
}
}
}
If you use a batch resolver for the author field:
With this optimization, you’ve reduced the number of records from N+1 to just 2, which is a substantial improvement. Moreover, it’s now independent of the number of records.
Here are some additional benefits of this solution:
Batch resolvers are currently only compatible with Lambda data sources, and this feature is not enabled by default. However, enabling this is very straightforward.

export function request(ctx) {
return {
operation: 'BatchInvoke',
payload: {
ctx: ctx
},
};
}
It’s as simple as that, but it offers significant performance gains to your GraphQL service.
Optimizing GraphQL queries in AWS AppSync is essential when building scalable and performant APIs — especially when dealing with nested data structures. The N+1 problem, while subtle, can lead to serious performance bottlenecks if left unaddressed.
By leveraging batch resolvers, you can drastically reduce the number of resolver calls, minimize round-trips to your data source, and deliver faster, more efficient responses to your clients. Whether you choose direct Lambda resolvers or pipeline resolvers, designing with batching in mind ensures your AppSync APIs are ready to perform at scale.
As your application grows, keeping an eye on resolver patterns and query performance becomes even more important. With the right strategy, tools, and architecture in place, you can build GraphQL services that are both elegant and efficient.